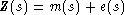
Á partir d’échantillons relevés sur le terrain, on cherche à déterminer la concentration par exemple d’un métal dans toute la zone. On utilise pour cela des modèles de distribution de la quantité intéressante.
Pour fixer les idées, notons z(s) la quantité de métal (par exemple en parties par million) en fonction de la position s (en dimension 2 ou 3). Les modèles étudiés ici approchent z(s) par Z(s) avec :
où m(s) est la tendance (trend en anglais) qui est déterministe (par exemple m(s) peut être constant ou égal à la distance à un fleuve, etc.) et e(s) représente la partie aléatoire de la distribution.
On dispose de n échantillons, donc de n mesures z(si) (1 < i < n) et il s’agit de trouver m(s) et e(s) qui permettent de prévoir z(s) le plus précisément possible (krigeage)
Une méthode d’estimation simple consiste à interpoler z(s) par les z(si) en mettant un poids proportionnel à l’inverse de la distance |s - si| au carré :

On se donne p fonctions fj(s) et on cherche des coefficients 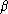 j tels que :
j tels que :
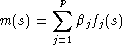
approche z(s) le mieux possible, “mieux” étant défini au sens des moindres carrés, on veut minimiser (z(s) - m(s))2 aux points d’échantillonage. Le plus équilibré consiste donc à minimiser :
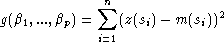
Pour trouver les j, on dérive g par rapport à 1, ..., p, on doit trouver 0 puisque la
fonction possède un extrêmum en ce point.
Exemple si p = 1 :
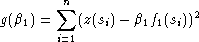
On dérive par rapport à 1 :
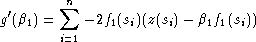
et on cherche 1 tel que g'(1) = 0 :
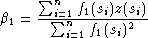
Si p = 2, on a :
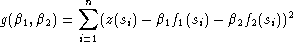
et en dérivant par rapport à 1 et 2, on obtient un système linéaire de deux
équations à deux inconnues :
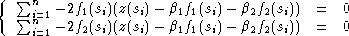
donc :
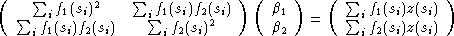
Dans le cas général, on a intérêt à utiliser les notations de l’algébre linéaire
(vecteurs et matrices). On note F la matrice à n lignes et p colonnes dont la j-ième
colonne est formée des valeurs de fj aux points s1, ..., sn et on note F* sa
transposée (c’est-à-dire la matrice obtenue par symétrie par rapport à la
diagonale). On note z le vecteur colonne formé par la valeur de z(s) en s1,..., sn
et le vecteur colonne formé par 1,..., p. On montre alors que vérifie
l’équation :
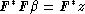
Pour la résoudre il faut donc inverser la matrice carrée F*F.
Remarques :
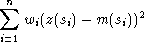
Dans une approche naive, on peut supposer que la partie aléatoire e(s) en un lieu est indépendante de e(s') en un autre lieu, et que la distribution de ces variables aléatoires est identique, on parle alors de modèle IID (independent identically distrbuted).
On peut aussi considérer que les parties aléatoires sont corrélées entre elles et ce d’autant plus que la distance entre s et s' est petite. Dans les modèles géostatistiques, on considère en fait que la corrélation ne dépend que de la distance entre s et s' et on estime cette corrélation à l’aide des échantillons si en calculant ou en modélisant le variogramme (ou le covariogramme) des si. Une fois ce calcul fait, on s’en sert pour pondérer le calcul de tendances au sens des moindres carrés.
Covariogramme:
On veut estimer la covariance des variables aléatoires e(s) et e(s'). On suppose donc
qu’elle ne dépend que de h = |s - s'|, la distance de s à s', on la note Cov(h). On fait
alors la moyenne de e(si)e(sj) pour tous les couples (i, j) de l’échantillonage tels que
|si - sj|  [h, h +
[h, h + 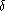 [ où est une constante, choisie de manière judicieuse : doit être
petit pour que la fonction covariogramme varie peu sur l’intervalle [h, h + [, mais il
faut aussi que cet intervalle contienne suffisamment de couples de l’échantillon pour
que la moyenne soit représentative.
[ où est une constante, choisie de manière judicieuse : doit être
petit pour que la fonction covariogramme varie peu sur l’intervalle [h, h + [, mais il
faut aussi que cet intervalle contienne suffisamment de couples de l’échantillon pour
que la moyenne soit représentative.
Une autre fonction, appelée variogramme, est souvent utilisée pour représenter la
corrélation de e(s) et e(s'), il s’agit de la moyenne de 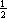 (e(si) - e(sj))2 pour
|si - sj| [h, h + [.
(e(si) - e(sj))2 pour
|si - sj| [h, h + [.
Il existe différents modèles de fonctions variogramme et covariogramme: le modèle
de la pépite par exemple qui décorrèle un échantillon du reste, des modèles continus
(sphériques par exemple). On peut à partir du variogramme de l’échantillon
déterminer les coefficients d’un modèle de variogramme approchant au mieux ce
vraiogramme, par exemple au sens des moindres carrés, cf. l’appendice A.1 de la
documentation du logiciel gstat disponible sur :
http://www.gstat.org
Lorsqu’on prend comme modèle des erreurs variables aléatoires e(s) telles que :
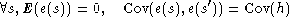
(E(e(s)) désigne l’espérance, c’est-à-dire la moyenne de e(s)), on adapte la méthode d’estimation par les moindres carrés à poids. On note V la matrice de coefficients :
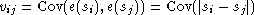
et z(s), m(s) les vecteurs :
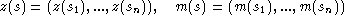
On minimise alors le produit scalaire :
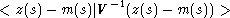
par rapport aux coefficients j pour déterminer ces coefficients j (et donc m). La
partie erreur en un lieu s0 est estimée par :
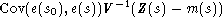
Les calculs sont un peu plus compliqués, la valeur optimale de est alors :
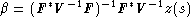
et on peut aussi calculer la variance de l’erreur e(s0), cf. la documentation logiciel gstat (appendice A.2).
Il existe des formats standard pour représenter les données des échantillons. Par exemple le format .eas utilisé par gstat, cf. sur pcm2 le fichier /usr/local/gstat/cmd/zinc.eas :
Zinc measurements on River Meuse flood plains 3 xcoord, m ycoord, m zinc, ppm 181072 333611 1022 181025 333558 1141 181165 333537 640 ... |
On lit les données dans le fichier et on les stocke dans un vecteur. L’élément de
base du vecteur sera composé de s et de z(s), par exemple ici s = (x, y) :
struct echantillon { double x; double y; double z; } ;
(x et y sont les coordonnées, z représente z(s)). Pour lire les données à partir du
fichier ci-dessus, par exemple :
...
ifstream infile("/usr/local/gstat/cmd/zinc.eas");
// on saute les 5 premieres lignes
char s[256];
for (int i=0;i<5;i++)
infile.getline(s,255);
// on lit les donnees ligne par ligne
vector<echantillon> v;
echantillon e;
for (;;){
infile >> e.x >> e.y >> e.z;
if (!infile) // si le fichier est termine on arrete la boucle
break;
v.push_back(e);
}
...
|
Calcul d’inverse de matrice : soit on dispose d’une librairie externe, soit on programme l’algorithme du pivot de Gauß(rappel de mathématiques: on colle la matrice identité à la matrice à inverser, on réduit, lorsqu’on a la matrice identité à gauche, alors la matrice à droite est l’inverse de la matrice de départ). Pour le choix du pivot à l’intérieur d’une colonne donnée, on choisit le nombre de valeur absolue maximale afin de diminuer les erreurs d’arrondi.
Pour le calcul du covariogramme, on pourra créer un type :
struct couple { echantillon un; echantillon deux; double longueur;};
On crée un vecteur v de n2 couples (vector<couple> v;) contenant tous les couples
d’echantillon (en calculant la longueur) et on ordonne ce vecteur par ordre
croissant en utilisant la fonction de tri sort (ajoutez #include <algorithm> pour
pouvoir l’utiliser). On définit la fonction de tri est_plus_pres :
bool est_plus_pres(couple a,couple b){
return a.longueur<b.longueur;
}
On trie le vecteur par :
sort(v.begin(),v.end(),est_plus_pres);
Il est ensuite aisé de déterminer pour des valeurs de h et données les couples dont la
longueur appartient à [h, h + [.
Remarque: la méthode la plus efficace pour trouver le premier couple dont la longueur est supérieure à h consiste à couper en deux moitiés égales le vecteur de couples. Si le couple du milieu a une longueur supérieure à h, on recommence avec la première moitié du vecteur, sinon avec la deuxième moitié, on s’arrête lorsqu’il n’y a plus qu’un couple dans le vecteur.